mirror of
https://github.com/linkedin/school-of-sre
synced 2026-07-06 02:10:33 +00:00
Moving image to Git for systems design
This commit is contained in:
@@ -19,7 +19,7 @@ Horizontal scaling stands for cloning of an application or service such that wo
|
||||
|
||||
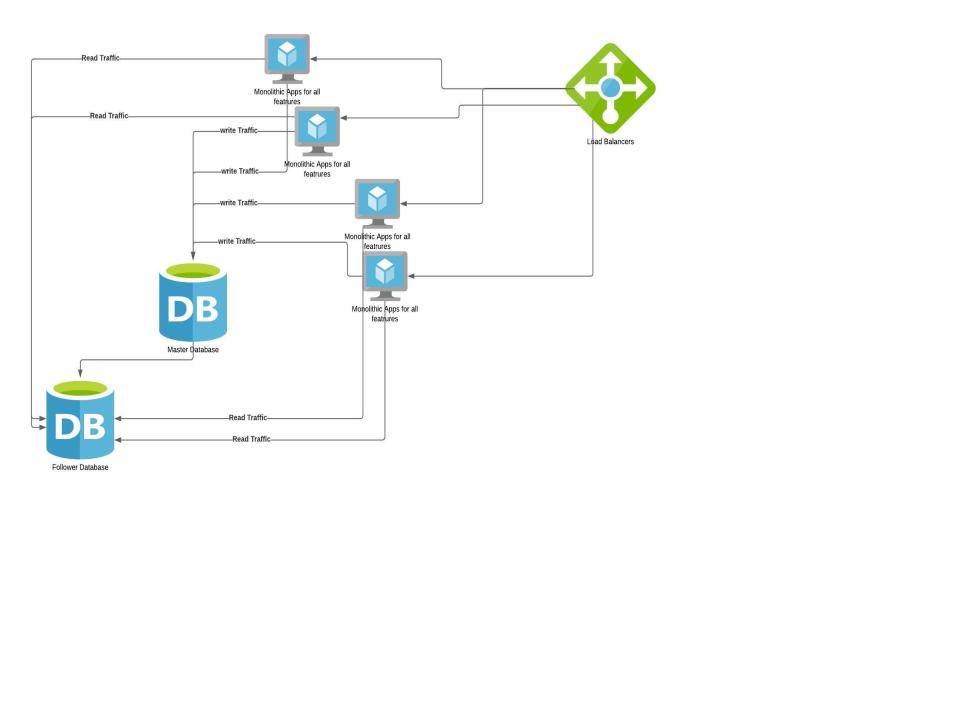
Lets see how our monolithic application improves with this principle
|
||||
|
||||
|
||||

|
||||
|
||||
Here DB is scaled separately from the application. This is to let you know each component’s scaling capabilities can be different. Usually web applications can be scaled by adding resources unless there is no state stored inside the application. But DBs can be scaled only for Reads by adding more followers but Writes have to go to only one master to make sure data is consistent. There are some DBs which support multi master writes but we are keeping them out of scope at this point.
|
||||
|
||||
@@ -94,7 +94,7 @@ More advanced client/server-side example techniques
|
||||
|
||||
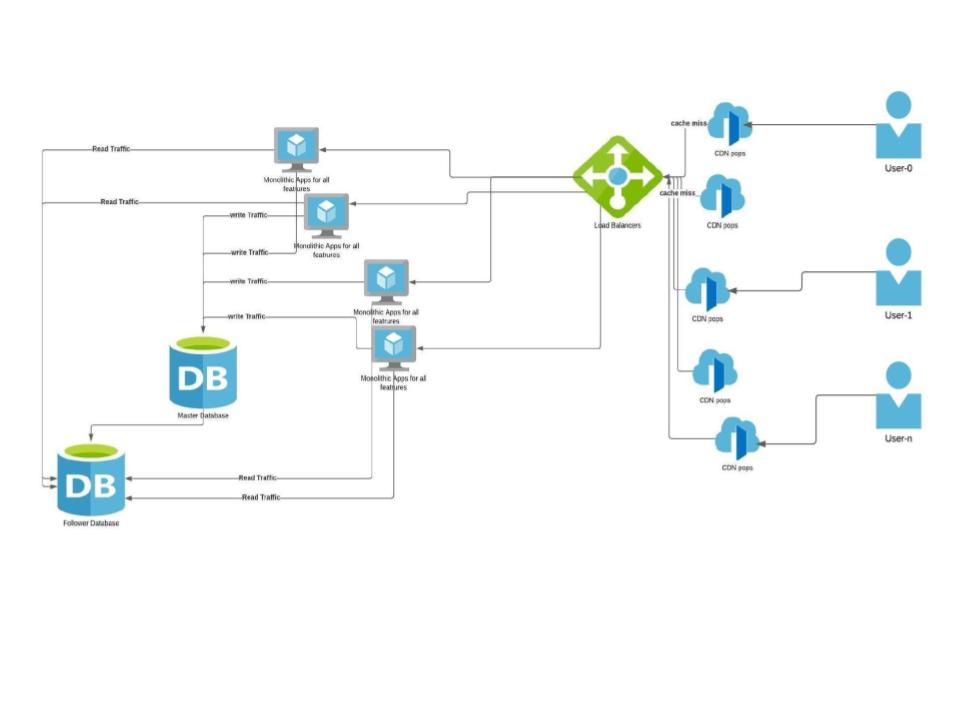
CDNs are added closer to the client’s location. If the app has static data like images, Javascript, CSS which don’t change very often, they can be cached. Since our example is a content sharing site, static content can be cached in CDNs with a suitable expiry.
|
||||
|
||||
|
||||

|
||||
|
||||
**WHAT:** Use CDNs (content delivery networks) to offload traffic from your site.
|
||||
|
||||
@@ -123,7 +123,7 @@ This pattern represents the separation of work by service or function within the
|
||||
|
||||
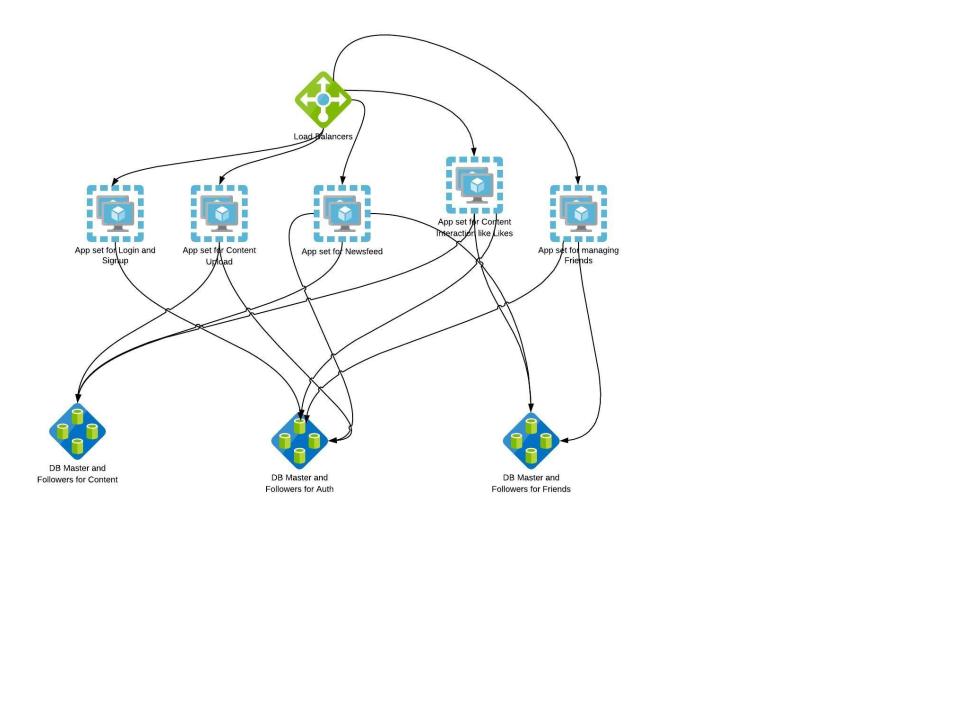
Microservices can scale transactions, data sizes, and codebase sizes. They are most effective in scaling the size and complexity of your codebase. They tend to cost a bit more than horizontal scaling because the engineering team needs to rewrite services or, at the very least, disaggregate them from the original monolithic application.
|
||||
|
||||
|
||||

|
||||
|
||||
**WHAT:** Sometimes referred to as scale through services or resources, this rule focuses on scaling by splitting data sets, transactions, and engineering teams along verb (services) or noun (resources) boundaries.
|
||||
|
||||
@@ -146,13 +146,13 @@ Very often, a lookup service or deterministic algorithm will need to be written
|
||||
|
||||
Sharding aids in scaling transaction growth, scaling instruction sets, and decreasing processing time (the last by limiting the data necessary to perform any transaction). This is more effective at scaling growth in customers or clients. It can aid with disaster recovery efforts, and limit the impact of incidents to only a specific segment of customers.
|
||||
|
||||

|
||||

|
||||
|
||||
Here the auth data is sharded based on user names so that DBs can respond faster as the amount of data DBs have to work on has drastically reduced during queries.
|
||||
|
||||
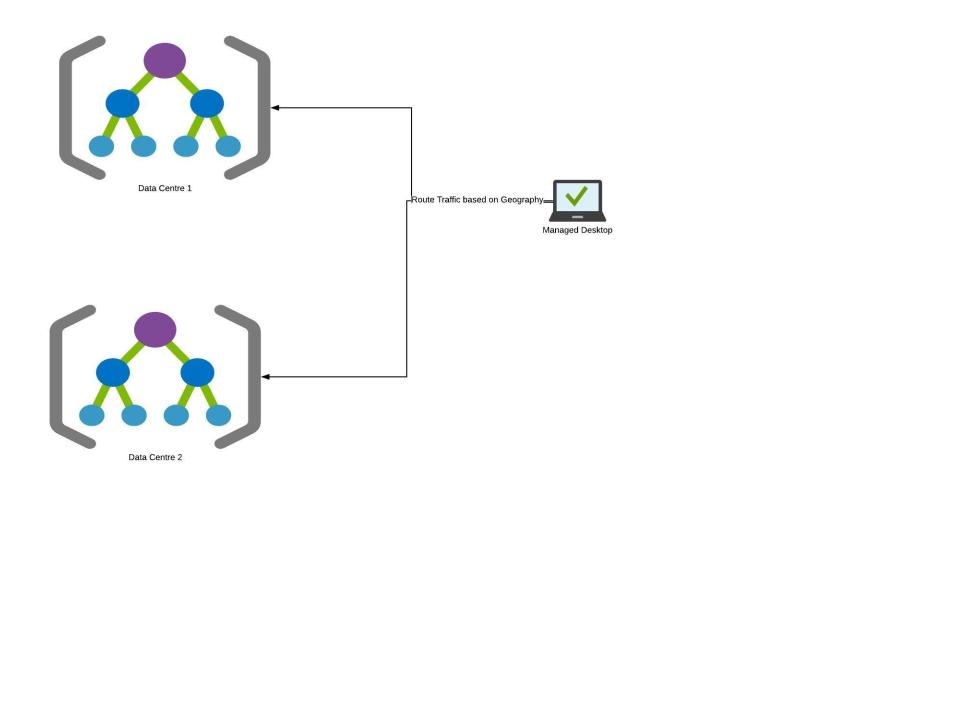
There can be other ways to split
|
||||
|
||||
|
||||

|
||||
|
||||
Here the whole data centre is split and replicated and clients are directed to a data centre based on their geography. This helps in improving performance as clients are directed to the closest Data centre and performance increases as we add more data centres. There are some replication and consistency overhead with this approach one needs to be aware of. This also gives fault tolerance by rolling out test features to one site and rollback if there is an impact to that geography
|
||||
|
||||
|
||||
Reference in New Issue
Block a user